Overview
Linear regression is a statistical method that models the relationship between a response (dependent) variable and some number of explanatory (independent) variables. It is a simple and commonly used technique for making predictions and estimating the response based on the values of the explanatory variables.

Ordinary Least Squares
Linear regression seeks to estimate the parameters of the linear equation that best fits the data. This equation with 

where 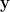






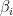


Estimating the regression equation’s parameters involves minimizing the residuals. The residual is the difference between the predicted value of a response and the actual value of the response. The ordinary least squares (OLS) method, which minimizes the sum of the squared residuals, is most commonly used for linear regression estimation. The OLS estimator for

Gauss-Markov Theorem and Limitations of Linear Regression
Linear regression relies on several assumptions for accurate results. These assumptions include
- Linearity:
- Independence:
, for
- Homoskedasticity:
- Normality:
![E[\mathbf{y}] = \mathbf{X}\boldsymbol{\beta}](https://s0.wp.com/latex.php?latex=E%5B%5Cmathbf%7By%7D%5D+%3D+%5Cmathbf%7BX%7D%5Cboldsymbol%7B%5Cbeta%7D&bg=ffffff&fg=000&s=0&c=20201002)
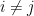


Violating these assumptions can affect the accuracy and reliability of the regression results. The Gauss-Martkov Theorem states that the OLS estimators are the best linear unbiased estimators (BLUE) when these assumptions are satisfied.
Additional limitations of linear regression include:
- Overfitting: Linear regression is sensitive to outliers or influential data points, which can result in overfitting. Overfitting occurs when the model is too complex and captures noise in the data, leading to a poor generalization of new data.
- Multicollinearity: Linear regression assumes that the explanatory variables are not correlated. If there is a high correlation between explanatory variables, called multicollinearity, linear regression can result in unstable estimates and difficulties interpreting the marginal effect of each explanatory variable.
- Limited Complexity: Linear regression models are only suited to capture linear relationships between variables. They may not be suitable for capturing complex, non-linear relationships often present in real-world data.
Despite these limitations, linear regression is a simple and commonly used statistical method that can provide valuable insights and predictions when used appropriately and when Gauss-Markov assumptions are satisfied. It is vital to assess the appropriateness of linear regression for a given data set and problem before using it for analysis or prediction.
Data Prep
Here, a simple linear regression with a single explanatory variable seeks to explain the variation in aid disbursements. The choice of the single explanatory variable comes from the variable with the lowest p-value in the multiple linear regression (MLR) with all quantitative predictors in the dataset. From the MLR, the 2021 CPI score, a corruption index, had the best linear predictive power among all possible explanatory variables. The other supervised learning methods performed classification tasks that required a categorical target variable. Here, linear regression requires a quantitative response, so total US aid disbursements (in US dollars) were used as the response. The categorical target variable “Aid Level” used in the other machine learning algorithms is a discretization of total aid disbursements. Since total aid disbursements are highly skewed, a log transformation of the response is appropriate for this analysis.

Code
Results
| Dependent variable: | |
| log_aid | |
| `CPI score 2021` | -0.117*** |
| (0.014) | |
| Constant | 21.282*** |
| (0.634) | |
| Observations | 168 |
| R2 | 0.295 |
| Adjusted R2 | 0.291 |
| Residual Std. Error | 3.195 (df = 166) |
| F Statistic | 69.505*** (df = 1; 166) |
| Note: | *p<0.1; **p<0.05; ***p<0.01 |

A one-unit increase in a country’s CPI score (less corruption) is associated with a 11.7% decrease in US aid disbursements to that country. This result is statistically significant at the 0.01 significance level. This model explains approximately 29.5% of the variation in US aid disbursements. With an F-statistic of 69.505, we can conclude that the this model fits the data better than the null model.
Diagnostics



These diagnostic plots show that most of the Gauss-Markov Assumptions hold for this regression. The residuals vs. fitted figure shows the residuals roughly, evenly spread around 0, with no apparent pattern. This plot supports the assertion of homoskedasticity and linearity in the data. The Q-Q plot shows that the standardized residuals mostly follow a Normal distribution; however, there appears to be some skewness in the lower tail. Since the data is sufficiently large (
Conclusions
In conclusion, this study found that there is a significant negative relationship between a country’s CPI score and the amount of US aid disbursed to that country. Specifically, a one-unit increase in the CPI score is associated with an 11.7% decrease in aid disbursements. This relationship is supported by the statistical significance of the regression model and the diagnostic plots that show most of the Gauss-Markov assumptions are met. Interestingly these results suggest that the US donates more foreign aid to countries with higher levels of corruption. These findings have important implications for policymakers and aid organizations in their efforts to combat corruption and promote transparency in recipient countries. The truth may be that the US donated to poor nations and poor nations are more likely to have corrupt leaders. A multiple linear regression analysis with additional variables could control for the prevalence of financial instability in countries with corrupt leadership.
